

WORKS 導入事例
模倣学習によるロボット制御の研究開発
模倣学習から始まるロボット制御の進化
ー VLAの可能性を見据えて ー
※2025年4月21日時点の記事です。
現場で求められるロボットの役割が、「決まった動作の再現」から、「柔軟に判断して行動」へと進化しています。
いま注目されているのは、VLA(Vision-Language-Action)という新しいAIの枠組みです。
これにより、ロボットの柔軟な対応が可能になり、人手不足の現場でもロボット導入のハードルが下がります。
1.VLAとフィジカルAI
VLA(Vision-Language-Action)とは、視覚情報(Vision)と自然言語(Language)を入力とし、
それに基づいて物理的な行動(Action)を生成するAIモデルです。
2025年3月、米Google DeepMind社はGemini2.0を基盤とする新しいAIモデル「Gemini Robotics」を発表しました〔1〕。
これは、ロボットを直接制御するために、従来のVLM(Vision-Language Model)に物理的な動作を出力として加えた、VLA(Vision-Language-Action)モデルです。
VLAは、VLMが視覚情報と言語情報を関連づけて画像やテキストを出力するのに対し、VLAはAIが現実世界を見て理解し、自ら行動を起こすことができます。
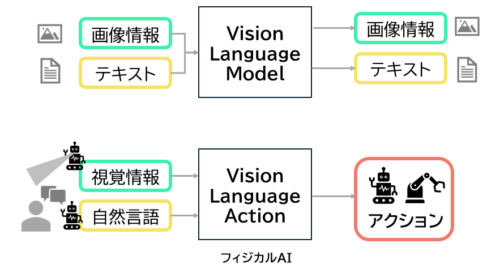
フィジカルAI(Physical AI)は、物理的環境と直接相互作用し、人間のように柔軟にタスクを遂行できるAIロボットを指します。
VLAにより、フィジカルAIのロボットはカメラなどのセンサーを通じて周囲の状況を認識(Vision)し、人間の指示や意図を理解(Language)し、実際に動いてタスクを実行(Action)します。
汎用性と人間とのインタラクティブなコミュニケーションが期待されます。
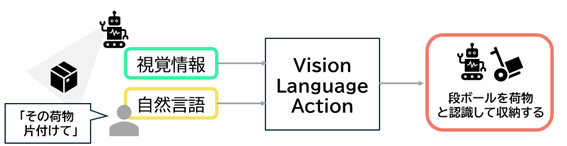
2.クフウシヤの取組み:模倣学習を用いたロボット開発
クフウシヤでは、模倣学習(Imitation Learning)に基づく動作制御を主軸としたPoC開発を進めています。
模倣学習は、人間が実演した動作のデモンストレーションデータから、ロボットが同様の行動パターンを学習する手法です。
将来的には、LLM(大規模言語モデル)も組み込み、VLAとして人間が指示してロボットが行動するモデルを目指します。
2-1. 作業補助ロボットの開発
クフウシヤでは、飲食・宿泊業などのサービス現場で使用される作業補助ロボットの研究開発を進めています。
(例えば、食事の配膳や、食事の片付けなど。)
従来のロボットは、単純な繰り返しや動作の再現が得意でした。
より複雑な作業補助が可能になることで、サービス現場での人手不足の解消を目的としています。
2-2. 模倣学習の軌跡
今回の実証実験では、バックヤードで食器やワイングラスを下げる場面を想定しています。
まず、配置した物体を掴み、移動させる行動を学習させます。
学習後は、任意の場所に置いた食器をロボットに認識させ、掴み、移動させる、という検証を繰り返します。
- step1:単腕で1個のグラスを掴む
まずは、1個のワイングラスを片方のアームで掴む検証です。
30回記録、1500回学習しただけでは、動作のがたつきが多く、まだ掴むことはできません。
50回記録、4000回学習を超えたあたりから、成功率が約50%に。
100回記録、4000回学習にて、成功率が70%を超えるようになりました。
学習状態の確認や、適切なepoch数の設定のために、lossの数値グラフを監視していました。
- step2:両腕で2個の物体を掴む
続いて、2個の物体を両方のアームで掴む検証です。
100回記録、4000回学習にて、成功率は90%。
ワイングラス1個での検証時の結果も踏まえて、定位置であれば、ほぼ成功することができました。
双腕ロボットへの学習には、アーム操作者が動作を実演することが前提です。
・・・そのため、人間が操作を習得するための時間を要しました💦
記録用データは、学習時間を長期化させないために、秒数制限を設定しています。
また、実証実験は最低限のGPUで検証するため、学習時間の短縮の工夫が必要でした。
- step3:グラス・皿の移動
次に、左右振定位置にある皿・グラスの移動です。
初期配置が複雑化し、必要な学習データは組合せで増加します。
100回記録、4000回学習にて、掴む動作は成功率100%、置く動作は成功率60%まできました。
置く動作では、配置されている皿にぶつかってしまう問題が発生。
移動させている皿やグラスが配置物の上を通るために、上に持ち上げてから置く動作を追加で学習させました。
継続して、カメラ設定や台形制御の調整により、動作精度を改善中です。
飲食・宿泊業などのサービス現場などでの活用を目指します。3.模倣学習xVLA 次のステップ
今後は、” 初期配置がバラバラでも柔軟に片付けられるロボット “を目指して実証を進めていきます。
【利用シーン】飲食店・宿泊業の配膳業務、バックヤードでの片付け・・・等
また、模倣学習とLLM(大規模言語モデル)を組み合わせ、最終的にはVLA型のインタラクティブなロボット制御へと発展させていく構想です。
PoCの段階から、社会実装に向けた高精度・高信頼の制御開発を行いたい企業様は、ぜひクフウシヤにご相談ください。
〔1〕https://blog.google/intl/ja-jp/company-news/technology/gemini-robotics-ai/
- step3:グラス・皿の移動
- step2:両腕で2個の物体を掴む





RELATED NEWS 関連ニュース
-

お知らせ 2025.02.03
当社が開発に携わっている大阪・関西万博「AIスーツケース」がプレスリリースされました
-

メディア掲載 2024.12.13
当社のオリジナル四脚ロボット開発についてご紹介いただきました
-

メディア掲載 2024.12.06
大阪・関西万博「AIスーツケース」の開発協力企業としてご紹介いただきました
-

お知らせ 2024.03.14
「はばたく中小企業・小規模事業者300社」を受賞しました
-

メディア掲載 2024.03.05
NHK福島 NEWS WEB特集にご紹介いただきました
-

お知らせ 2024.03.04
当社が開発したロボットシステムがUNIVERSAL ROBOTS社のUR+ソリューションとして認証されました